一次排查python asr服务内存泄漏的经历
最近小宇宙的asr系统python服务出现有规律性的内存泄漏,容器crash重启现象,具体表现在如下监控
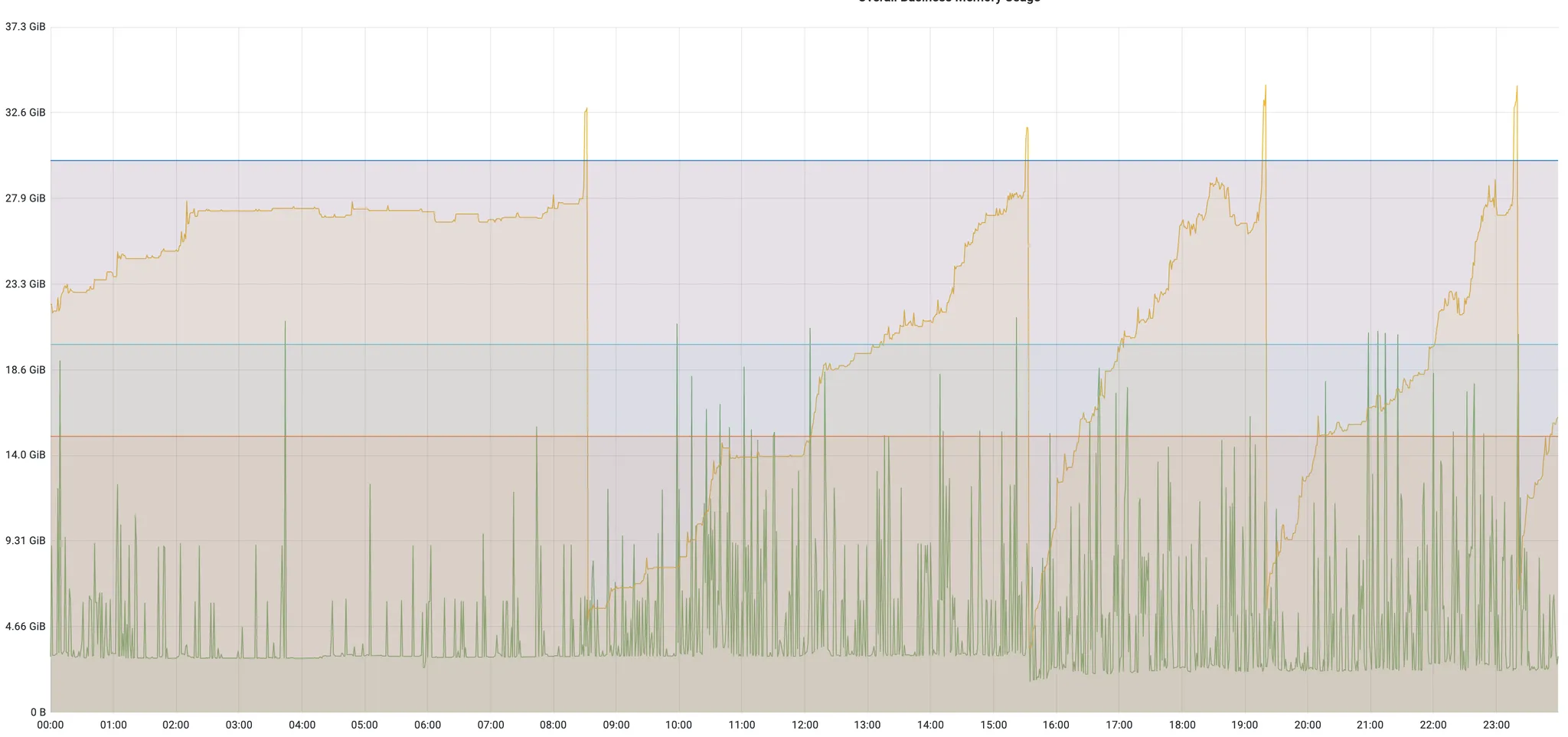
asr服务最近上线的新功能是接入了vibevoice模型,在此之前从没有发生过内存泄漏,于是立刻把问题定位在vibevoice部分的代码。这次的排查全程在ClaudeCode的协助下完成。
首先让ClaudeCode定位到可能出问题的代码,然后给出如何追踪服务在运行过程中的内存情况。ClaudeCode增加了tracemalloc 以及快照的调试接口。我便开始在服务器上部署调试镜像,调用模型,记录快照,最后把快照的输出发给ClaudeCode分析。vibevoice的模型接入逻辑是把音频转成base64字符串,然后再通过http接口发送给真正的模型推理服务,获得转录结果。ClaudeCode猜测是音频的base64字符串和大json,在调用推理接口报错时,全部会被 traceback 的 frame locals 死死引用。它给出了以下修复代码
1 | # _stream_transcription |
按照它的修复,我重新发版测试了一下,效果还是不好,于是我继续把内存追踪快照结果发给它分析。紧接着它分析出了第二个问题:C 扩展堆 / glibc 碎片
它建议我添加MALLOC_ARENA_MAX=2和PYTORCH_ALLOC_CONF=expandable_segments:True 这两个环境变量。我照做了,发版后再次测试,神奇的事情发生了,内存确实不再一直增长,而是增长一部分后就稳定在了固定水平,问题解决了。